The launch of Sora has raised a crucial question in the AI community: what makes this model so superior to previous AI video generators like Runway’s Gen-2 or Pika Labs? The answer lies in the architecture and the approach adopted by OpenAI for managing spatio-temporal coherence.
This technical breakdown, which complements our overview of the AI Video Revolution Sora (see our Article : Sora and the AI Video Revolution), focuses on the innovations behind this performance.
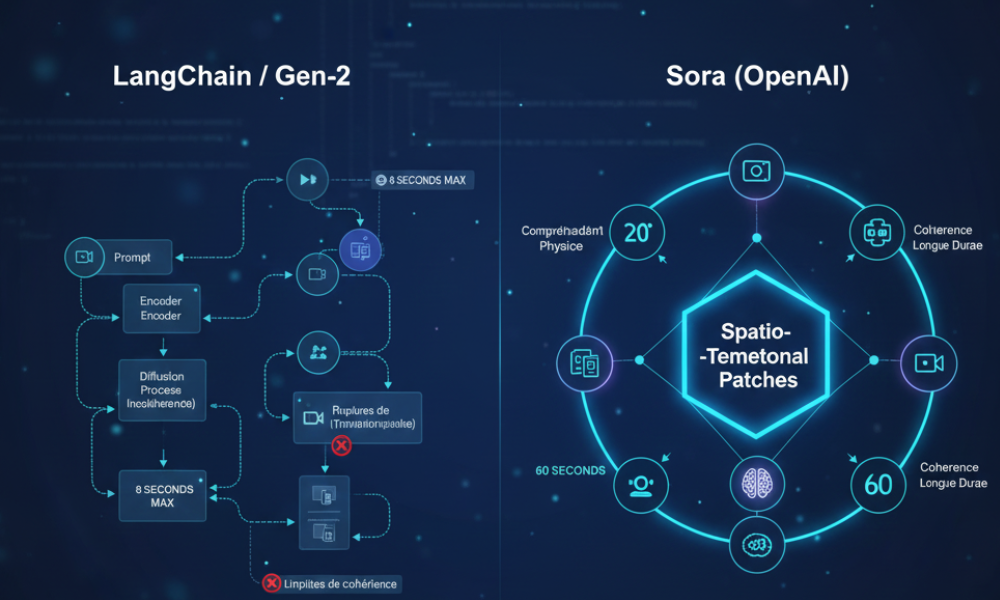
1. The Model Architecture: Spatio-Temporal “Patches”
Unlike models that treat video as a series of individual images (an approach that causes a loss of coherence between frames), Sora uses a unified approach.
Sora uses what OpenAI calls “patches” for video, similar to those used to transform static images. These patches are not only spatial (like a square on an image), they are spatio-temporal: they represent small video cubes (a spatial area over a short duration).
- Advantage: By training the model on these blocks of movement, Sora intrinsically learns the dynamics of space and time simultaneously, allowing for the generation of longer and more coherent sequences.
2. The Large-Scale Diffusion Model
Sora builds on the concept of diffusion models (used in DALL-E) by extending it to four dimensions (height, width, depth, and time). The model starts with random “noise” and gradually transforms it into a coherent video that matches the text prompt.
The large scale of data used in training has allowed Sora to acquire a “general understanding” not only of appearances but also of physical interactions.
3. Sora vs. Gen-2 and Pika: Temporal Coherence
Historically, the weakness of all video generators has been temporal coherence.
| Feature | Sora (OpenAI) | Gen-2 (Runway) / Pika Labs |
|---|---|---|
| Max Duration | Up to 60 seconds. | Typically 4-8 seconds. |
| Object Coherence | High. Objects persist without randomly changing shape. | Low to Moderate. Objects may flicker or transform. |
| Scene Change | Ability to generate complex shots and transitions. | Generally a single static shot or with little camera movement. |
| Prompt Understanding | Excellent, even for complex cinematic instructions. | Good, but can struggle with specific details. |
Sora overcomes duration limits by being able to anticipate the logical evolution of scenes for an entire minute, a huge leap that significantly reduces the need for manual editing or looping.
4. Current Limitations and “Failures”
Even with these advances, Sora faces challenges, proving that it still acts as an advanced simulator rather than a perfect observer of the world.
- Causality: It can sometimes ignore obvious cause-and-effect relationships (for example, an object may hit another without moving it correctly).
- Simple Physical Interactions: It may fail on fine tasks like precise gripping or detailed interaction between a character and a specific object.
These limitations show that while Sora is a “giant step” toward simulating reality, there is still progress to be made before it achieves the ability to perfectly simulate the physical world.





